Root
My personal knowledge companion
495 commits · last on Mar 7, 2026
Root is a personal knowledge companion designed to help me retain, connect, and reflect on the information I consume.
I spend a lot of time listening to podcasts, watching long-form interviews, and reading books. Yet too often, valuable ideas slip through the cracks. I vaguely remember that I heard something interesting, but not where it came from, why it mattered, or what I actually thought about it at the time. In conversation, I often remember a relevant stat or quote but can’t quickly find the exact source:
- “I remember hearing something like X in a podcast once.”
- “What podcast did I hear that fact in?”
- “What were some interesting stats from that book?”
- “What were my core takeaways from this source?”
The inability to reference specific sources of information, as well as retain and remember core learnings has led to lots of frustration. Having spent much of my life learning about investing, I understand the power of compounding: small, consistent gains accumulate into something incredible over time. In an age where AI can generate information effortlessly, the advantage of humans has morphed into their experience, taste, and judgment. Root is my attempt to help me compound learning itself.
What Root Actually Does
Root is built around a simple idea: true learning only occurs if you actively engage with the material you consume.
Instead of treating books, podcasts, and articles as disposable streams of information, Root turns them into structured, revisitable objects. Every source you add becomes a place to add citations, takeaways, and your own thoughts.
At its core Root consists of a few fundamental primitives:
Sources
Everything starts by creating a source: a book, podcast, interview, or article. Sources act as anchors, giving every idea a clear origin and preventing insights from becoming detached or misremembered.
Citations
Citations are references from the source material. They capture concrete stated facts or quotes as they appear in the source. They are precise, attributable, and bereft of interpretation. This separates information and reflection.
Captures
Captures are your in-the-moment reactions and comments — your own thinking in response to what you just read or heard. Think of them as margin notes: constrained to a specific source, tied to a specific moment.
Takeaways
Takeaways are synthesized insights from a source: patterns you notice, arguments that emerge, or ideas that are worth remembering. Root limits these per source: this forces you to distill sources into a maximum of 5 takeaways.
Notes
Notes are long-form essays or reflections that sit above individual sources. Where takeaways distill a single source, notes let you synthesize across many — weaving together citations and themes from different books, podcasts, or interviews into a coherent argument or idea.
Search & Retrieval
As your library grows, Root makes it easy to ask questions about your takeaways, citations, or captures. It doesn’t just regurgitate summaries, but surfaces and references specific citations and takeaways to support its answer.
Review
In progress: an interactive review system designed to help users retain specific information from their sources.
Guiding Principles
While Root has some “AI Powered” features, it is intentionally AI-assisted, not AI-driven. Real learning comes from friction and AI can often rob us of that friction.
Low friction, high fidelity — Knowledge should enter the system easily, but original source context is always preserved. A citation without its origin is just a floating quote.
Compounding value — The more you add, the more valuable the system becomes. Every highlight, capture, and note makes future retrieval and synthesis richer. This is the same logic as compounding returns: small, consistent deposits accumulate into something significant over time.
Incremental refinement — Insights aren’t fixed. A takeaway you write today might look different after you’ve read three more books on the same topic. Root is designed to support that evolution rather than freeze your thinking at a single point in time.
How I Use Root
Reading
I upload PDFs directly into Root and highlight text as I read, the same way you’d mark up a physical book. The act of deciding what’s worth highlighting is itself part of the learning — it forces active engagement rather than passive absorption. Highlights become citations I can reference later, search across, and pull into notes.
Podcasts & Interviews
With podcasts and YouTube interviews, Root generates a transcript and lets me highlight directly in it. In practice, I’ll put on my headphones while making breakfast, and when I hear something worth saving, I’ll hop over to my laptop and highlight it in the transcript. Reading back what I highlighted after the fact helps reinforce the ideas — it’s a second pass that sticks better than just listening once.
Synthesis
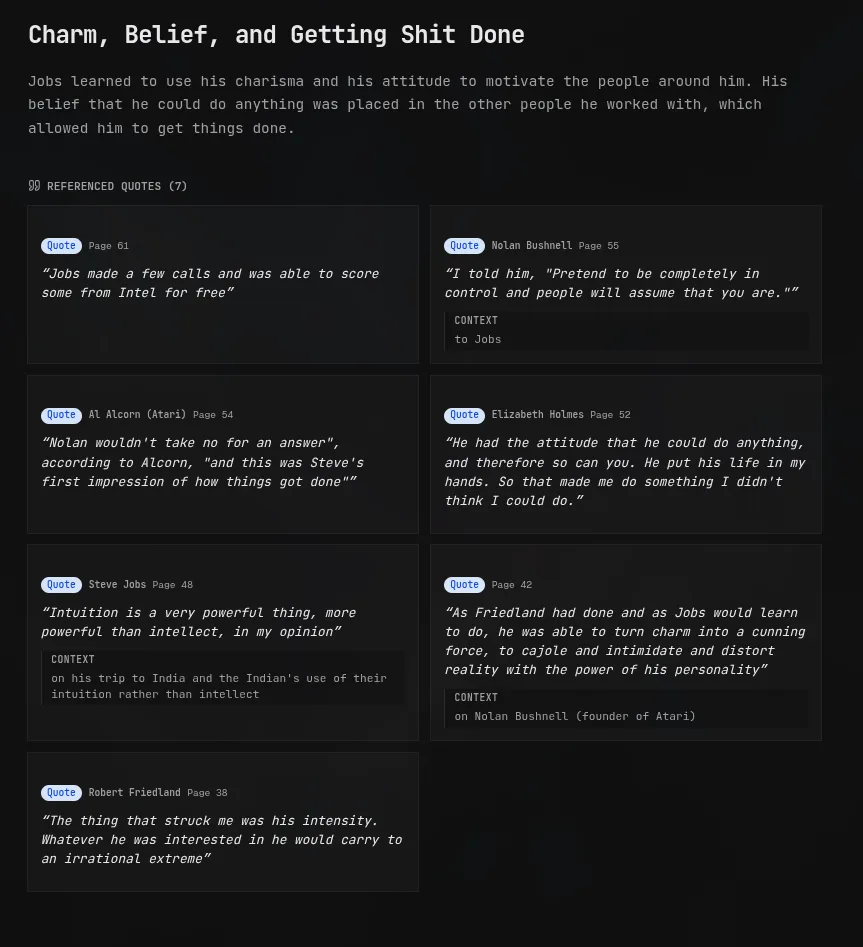
As I’m finishing a source, I’ll often notice a recurring theme and start drafting a takeaway. I’ll give it a rough title and attach citations as I go. For example, while reading the Steve Jobs biography, a pattern that stood out early was his ability to persuade through charm and conviction; I created a takeaway around that theme and linked supporting quotes as they surfaced. When the same idea starts appearing across multiple sources, that’s when I’ll open a note and start writing something longer.
Roadmap
- Learning Engine (refined review system)
- Kindle ingestion (chrome plugin)
- Quotes from Webpages
GitHub Activity
Commit history from project inception (up to 1 year).
Last updated Mar 12, 2026
Monthly Breakdown
Jan 21, 2026 — Consolidated Ingress + Deploys
This iteration added a single entry point (Nginx) to simplify deployments, improve rate limiting, and make auth enforcement consistent across services.
Services
- Frontend (Next.js + Better-Auth): UI, routing, and session handling. Proxies API calls and reads auth/session data directly from Postgres.
- Nginx Gateway: Single ingress for
/go-apiand/rag-api, with rate limiting and routing. - Go API: CRUD, domain validation, and core write paths for sources, citations, captures, and tags.
- Python RAG Service: Embeddings, vector search, transcript workflows, and SSE streaming for LLM responses.
- Database (Postgres + pgvector): Source of truth for user data, metadata, and embeddings.
- External Services: LLM providers, embedding providers, transcripts, storage, and media APIs.
Dec 14, 2025 — Split RAG into Python
Early on everything lived in Go. I tried tool calls and RAG there, but it was verbose and slow to iterate. I then routed RAG through Go → Python, which added an extra hop and made the system feel like a brittle distributed proxy. The cleanest move was giving the Python service auth directly via JWKS, so the frontend could call it without a Go bridge.
I also moved the database from self-hosted Postgres on Dockploy to Neon for easier table visibility, safer backups, and less anxiety about losing data.
Services
- Frontend (Next.js + Better-Auth): UI plus proxy routes to Go and Python, adding JWTs on requests.
- Go API: CRUD and domain validation for the core app data.
- Python RAG Service: Vector search and LLM workflows, authenticated via JWKS.
- Database (Postgres + pgvector): Stores user content and embeddings.
- External Services: Embeddings + LLM providers.
Early Dec 2025 — Go Monolith
The first version was a single Go API focused purely on CRUD while I figured out the core entities and data model. This choice was primarily motivated by wanting to learn to use Golang and not having any prior experience using it. It worked well for basic operations. I briefly allowed server-side Drizzle reads to move faster during development, but dropped that to avoid splitting read paths and to keep a single, consistent CRUD interface through the Go API.
Services
- Frontend (Next.js + Better-Auth): UI and session handling, proxying everything to Go.
- Go API: CRUD only, no AI or RAG operations.
- Database (Postgres + pgvector): Stores user content and embeddings.
- External Services: Embeddings + LLM providers.
Monday, 2 Mar 2026 - Sunday, 8 Mar 2026
Launched Notes, bridging reading and long-form thinking in one place.
Major Features
- Notes V1: A rich-text writing environment where notes can stand alone or link to highlights from your reading.
- Citation Embeds: Inline citations can be inserted directly into notes, keeping your writing grounded in the sources it draws from.
- Autosave & Drafts: Notes save automatically and persist locally, so work is never lost between sessions.
Minor Features
- Added a sticky header that reveals on scroll for better navigation on long pages.
- Improved saving feedback across forms to handle network edge cases more gracefully.
Maintenance
- Implemented all note-related endpoints and data relationships in the Go API.
- Refactored backend store and repository patterns to support note-to-highlight relationships.
Monday, 23 Feb 2026 - Sunday, 1 Mar 2026
A week of active use and frontend refinement — improving the durability and feel of the media experience.
Major Features
- Source Page Refactor: Decomposed the monolithic source detail view into specialized, type-safe pages (
Podcast,Video,Pdf, andDefault). This reduced client-side complexity and improved page load performance. - Podcast Archiving: To prevent timestamp drift and broken links, podcast audio is now automatically archived to R2 storage upon transcript generation.
- Media Hotkeys: Added comprehensive keyboard shortcuts for the YouTube player (Space to play/pause, Arrow keys for 10s seeking) with smart focus management to prevent hotkey “swallowing” the embedded player.
Minor Features
- R2 Storage Durability: Switched from storing volatile presigned URLs to persistent R2 keys, generating fresh URLs on-demand to avoid expiration issues.
- Optimistic UI: Added optimistic updates for source section summaries, making the organization workflow feel instantaneous.
- Design: Public Profiles: Drafted and documented the visibility model (
none,feed,public) to prepare for the upcoming social and sharing features.
Maintenance
- Implemented a unified R2 storage interface in the Go backend for consistent file handling.
- Fixed a bug where the command palette could fail to navigate to specific source types.
Monday, 16 Feb 2026 - Sunday, 22 Feb 2026
Focused on refining the RAG experience with better tool orchestration and UI responsiveness, alongside UX improvements for media and manual workflows.
Minor Features
- Implemented tool call filtering to improve agent reliability.
- Refactored and improved loading states in the frontend for RAG, providing better feedback during multi-step reasoning.
Maintenance
- Refined podcast listening and manual workflows to identify and resolve UX friction points.
Monday, 9 Feb 2026 - Sunday, 15 Feb 2026
Highlights and transcript improvements to support better editing workflows.
Minor Features
- Removed text-based match requirement for highlights in the transcripts tab. This allows users to edit and clean up transcript highlight content (e.g., correcting misspelled names) before saving.
Monday, 2 Feb 2026 - Sunday, 8 Feb 2026
Performance-focused week aimed at stabilizing transcripts—plus a big new source type.
Major Features
- PDF support with highlights: upload PDFs, select and highlight text, persist highlights to DB, and include them in RAG retrieval. Forked and improved an open-source PDF highlighting library to fix underlying API issues.
Minor Features
- Added optimistic updates for PDFs and transcripts to avoid laggy UI feedback.
- Hid the incomplete review feature in the UI while it matures.
- Reworked dialog system and added pickers for more composable workflows.
- Reworked citation location storage to support long-term versioning and clarify derived vs manual locations across BE and FE.
- Improved dialog and picker flows for async behavior, error handling, and workflow chaining.
Maintenance
- Fixed massive re-rendering issues in the transcripts tab to resolve major performance regressions.
- Temporarily removed video timestamp sync to keep transcript playback responsive.
- Moved FastAPI telemetry to Logfire for stronger OpenTelemetry support.
- Cleaned up AGENTS.md and Claude docs to keep agent guidance in sync with current best practices.
- Removed dead code across the project to reduce maintenance overhead.
- Switched nginx to a custom-built image so config changes trigger rebuilds and redeploys; removed bind mounts and baked config into the image via
nginx/Dockerfile. AddedX-Config-Revresponse header to verify the running config after deploy.
Monday, 26 Jan 2026 - Sunday, 1 Feb 2026
Started the week with PWA foundations and mobile-readiness.
Major Features
- Basic PWA support with
manifest.jsonfor home screen installation. - Consolidated dialogs into one
citationDialogwith optional notes and other parameters. - Citations can now belong to multiple takeaways (many-to-many); selecting a citation in the takeaway editor is no longer blocked if it’s already used elsewhere.
Minor Features
- Mobile UI enhancements and improvements.
- Added amber “In X takeaways” badges to citations in the highlights tab and takeaway editor, with tooltip showing takeaway titles on hover and click-to-navigate when there’s only one takeaway.
- In the “Add to Takeaway” dialog, takeaways already containing the citation are now visually disabled.
Monday, 19 Jan 2026 - Sunday, 25 Jan 2026
Short week focused on security, deployment hygiene, and improving the API entry point.
Major Features
- Created Production environment for all services
- Implemented embeddings and vector search support for source summaries.
Minor Features
- Enabled model selection in the Ask feature, plus a reasoning dropdown.
- Added CAPTCHA for login, signup, and other auth flows.
- Added source section summaries and displayed them on the overview page.
Maintenance
- Fixed bug in the context menu for editing highlight-items.
- Fixed bug in edit-section dialog which would delete summary field
- Fixed bg color of mention modal to adapt to Color theme
- Simplified the architecture via Compose in Dokploy and added Nginx as a single API entry point with rate limiting.
- Cleaned up and removed old env vars that were over-engineered or no longer necessary.
- Deployed a new production instance and migrated all data from dev to prod.
- Removed unused schema columns (e.g., nested
source_sectionswithparent_id) to reduce FE/BE complexity. - Started using Doppler locally to sync env vars across machines and setups.
- Improved Makefiles for better local UX (seeding DB, creating test users, starting services).
Monday, 12 Jan 2026 - Sunday, 18 Jan 2026
Big week shipping transcripts across video and podcast sources, plus UX and architecture upgrades.
Major Features
- Transcripts for videos (YouTube) with Webshare proxying to avoid blocking.
- Transcripts for podcasts: RSS ingestion, shows in DB, episodes in DB, and on-demand transcripts via AssemblyAI.
- In-app podcast and YouTube players so you can listen/watch while reading transcripts.
Minor Features
- Added a transcript timestamp location type for transcript-based notes vs manual notes/citations.
- Improved the Cmd+K dialog with smoother movement and quick navigation to sources.
- Added keyboard shortcuts across pages (e.g., O = Overview, T = Transcript, S = Sections/Highlights on a Source).
- Migrated to base-ui in shadcn with the Lyra preset (boxier UI, replacing Radix UI).
- Added hover behavior for sidebar tooltips.
- Created a clearer transcript dialog flow (UI no longer mirrors BE storage directly).
Maintenance
- Improved transcript rendering performance, especially highlight rendering.
- Removed SSR to simplify data loading and state management.
- Upgraded and re-embedded everything with Voyage 4.
- Set up R2 storage connections and credentials for multiple buckets.
- Refactored FastAPI for better separation (routers, services, repositories).
Monday, 5 Jan 2026 - Sunday, 11 Jan 2026
Admin tooling and quality-of-life week, plus embedding and ranking upgrades.
Major Features
- Built out the admin UI with user stats (citations, captures, takeaways) and trends.
- Added admin user stats API endpoints and repository layer to support the dashboard.
Minor Features
- Added Meta/Ctrl + Enter submit in forms.
- Batched embedding calls in the admin UI.
- Upgraded reranking to v2.5 with instructions.
- Switched to
voyage-3-largeembeddings at 1024 dimensions via matryoshka embeddings.
Maintenance
- Fixed lots of small bugs and added additional loading states.
- Updated documentation with best practices.
- Removed deprecated code from the Go API (old River queue logic).
Monday, 29 Dec 2025 - Sunday, 4 Jan 2026
Review system foundations and RAG search upgrades.
Major Features
- Shipped review system v1 backend foundations (schema, services, handlers) plus review generation endpoints.
- Built LLM-based review item generation with structured prompts and validation.
- Added BM25 as an additional search path for Ask (hybrid retrieval improvements).
Minor Features
- Added takeaway support to the RAG pipeline.
- Started the review feature module on the frontend and added design docs for review UX.
Maintenance
- Fixed SQL issues in review streak calculations and cleaned up duplicate queries.
- Refactored frontend utilities for clearer separation of concerns and improved docs.
- Removed deprecated Go API code and tightened configs.
Monday, 22 Dec 2025 - Sunday, 28 Dec 2025
Moved the product to a cleaner Go-API-first architecture while strengthening RAG responses with richer citation context. The RAG service also went through a round of agent and ORM refactors to make the new pipeline more reliable.
Major Features
- Completed the migration of sections, takeaways, captures, and related CRUD to the Go API, removing remaining Drizzle routes to make the Go backend the single source of truth.
- Added citation speaker/context metadata to RAG capture retrieval so answers and reference chips expose more context.
- Introduced Jetflow-based agent orchestration and refactored the RAG service around modular actions.
Minor Features
- Added an unsorted captures endpoint to support surfacing unorganized items.
Maintenance
- Consolidated frontend data access to generated Go API types and removed legacy query/data layers.
- Added tooling for cloning dev data and updated RAG service dependencies and docs.
Monday, 15 Dec 2025 - Sunday, 21 Dec 2025
This week focused on a new RAG agent foundation, admin tooling, and backend organization improvements. Several UX and reliability cleanups landed alongside the structural work.
Major Features
- Introduced a Jetflow-based RAG agent architecture to power multi-action search and orchestration.
- Added admin UI and API support for user stats and basic admin workflows.
Minor Features
- Fixed create-capture dialog overflow and related source-detail UI edge cases.
Maintenance
- Reorganized Go backend packages for reuse and clarity.
- Added Cypress smoke testing scaffolding and refreshed documentation and scripts.
- Refactored the RAG service toward an ORM-backed data layer.
Monday, 8 Dec 2025 - Sunday, 14 Dec 2025
RAG V1 landed end-to-end, including embeddings, hybrid retrieval, and streaming responses, and then moved into its own Python service. Tagging and takeaways continued to mature on the frontend.
Major Features
- Shipped RAG V1 with Voyage embeddings, hybrid retrieval, and grounded LLM answers with streaming.
- Migrated RAG to a Python microservice with a Go proxy and client interface.
- Added Tagging V1 and expanded tagging across core entities.
Minor Features
- Expanded takeaways with view/edit flows and section editing improvements.
- Refined the command palette and unsorted citations UX.
Maintenance
- Improved RAG logging, error handling, and SSE stability.
- Updated schemas and tightened security/documentation updates.
Monday, 1 Dec 2025 - Sunday, 7 Dec 2025
The project shipped a major cleanup pass with structured notes, new citation metadata, and a streamlined UI. Core source and capture flows were upgraded, while the recall feature was removed.
Major Features
- Reworked citations into structured locations and sections, plus new capture CRUD and highlight flows.
- Added speaker and context fields on citations and support for standalone captures.
- Removed recall features across backend and frontend.
Minor Features
- Introduced theme-based colors and polished home/source layouts.
- Fixed sidebar state persistence and dialog UX glitches.
Maintenance
- Refactored backend organization and validation, plus environment/config cleanups.
Key Takeaways
Deployment & Infrastructure
- Docker Compose vs. Individual Dockerfiles: Switching to Docker Compose allowed me to more clearly see exactly what variables are needed for specific services. In Dockerfiles, it’s often not that clear-cut since you’re just injecting environment variables. Seeing it all defined in a single
docker-compose.ymlis significantly more useful for maintaining a clear overview of service dependencies and configurations.
Language & Tooling
- Golang: Go is really great. Its error-first approach is kind of nice and makes you think about errors early. However, if you’re developing a product while trying to figure out the kinks, it’s a little slow since it’s so verbose (especially if you’re doing DB migrations etc). That said, its declarative approach is really nice—compared to something like Spring Boot where everything is super “magicky,” in Go, 99% of behavior is explicitly defined somewhere.
UX and Development
- Super easy to begin supporting a DB schema before properly validating this field / feature is required.
- What might make more sense is to keep it in JSONB Metadata until you can prove it drives value, then extract into it’s own property